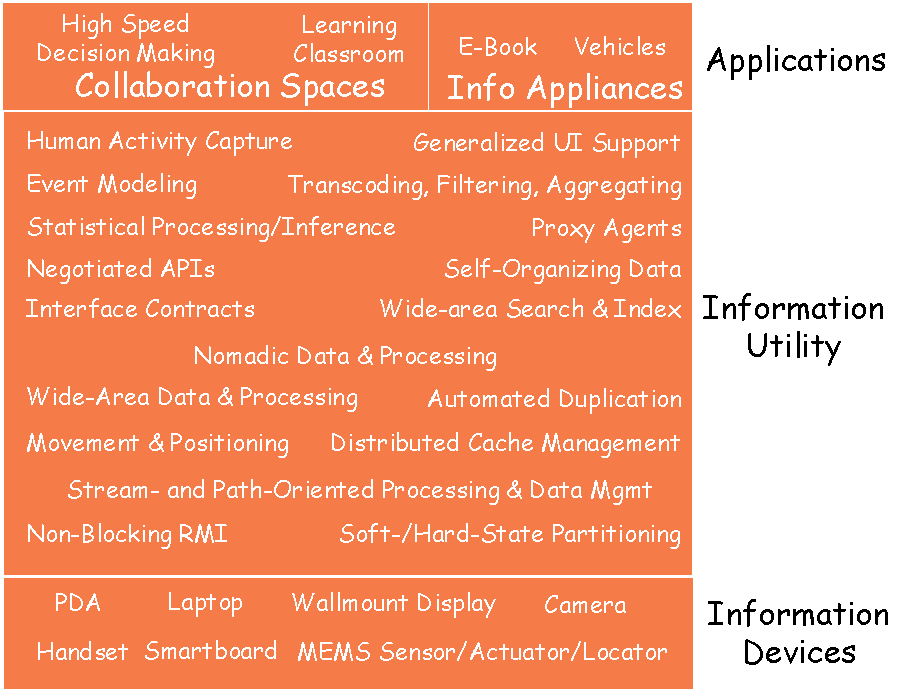
The base program maps out the system architecture we have envisioned. In this section, we concentrate more on what we will not do, as the descriptions of the individual options speak in considerable detail about the key technical components they propose to develop.
Information Devices: Option 1 discusses the range of devices we would like to support with the Information Utility. In the base program, we will restrict ourselves to a small diversity of commercially-available devices. There will be no hardware design. Commercially-available devices will be installed in Soda Hall to provide a small-scale testbed to support Utility and Application development, and to enable usability evaluations.
Information Utility: Options 1, 2, 3, 4, and 5 develop components for the Information Utility: support for diverse devices (Option 1), fluid software (Option 1), "always available" functionality and administrative scalability (Option 1), pervasive fluid storage sys-tems (Option 2), sensor-centric information management (Option 3), component cooperation/negotiation mechanisms (Option 4), and techniques for tacit information extrac-tion and exploitation (Option 5). The Base Program concentrates on the fundamental technologies to enable fluid software (Options 1, 2, 3) and information extraction and re-use (Options 3, 5, 6):
(i) Partitioning and management of state between soft and persistent state: This enables processing and data to flow to where it is advantageous to be located (Option 1). It also enables "always available" functionality, in that heavy weight recovery mechanisms are focused on persistent state and are not needed for soft state (Option 1).
(ii) Data and processing placement and movement: This is an enabler for fluid software. It automates the building translation, aggregation, and filtering pipelines (Option 1). Per-vasive severless storage management enables the staging and movement of data through-out the environment (Option 2). Integrating sensor capture with repositories provides a context for developing these techniques (Option 3).
(iii) Component discovery and negotiation: Fluid software is enabled if they can adapt their interfaces to facilitate assembly into processing cohorts. This is accomplished by techniques for components to discover and locate other components, advertise their capa-bilities, and enter into negotiations to customize functionality and interfaces (Option 4). These will be developed within the context of cooperating information sources, stor-age/processing services, and their policies for rendering their services (Options 2, 3).
(iv) Flexible capture, self-organization, and re-use of information: Our strategy for mak-ing people more effective is to help them leverage the work of others. It is important to capture the by-product of human activities, organize them for access and retrieval, and make it easy to re-use by others. This will be pursued in the capture of sensor sources (Option 3), extraction of tacit information (Option 5), with the underlying technologies for the pervasive storage system (Option 2) and storage management (Option 3).
Applications: The Base Program focuses on limited applications. We will develop these to drive the underlying Utility. Our testbed can be used for both teaching and brain-storming, with limited camera, display, and sensors. Limited groupware will be devel-oped, to create streams for tacit information extraction and exploitation (Options 5, 6). These will be chosen to build on the prototype Information Utility's fluid software.
Design Methodology: Usability evaluations will focus on the limited components devel-oped in the Applications. The system design methodology (Option 7) will focus on for-mal methods and how this can assist in partitioning applications into fluid, communicat-ing components that meet their interface and functionality contracts (Options 1, 4).
A notional architecture for the system we intend to build is shown in Figure 2. The technologies drawn on by the base program are described in more detail in the following.
The system design challenge of the next decades is the dramatic expansion of device diversity, where all devices are interconnected, with communication capabilities roughly in proportion to their processing capabilities. Small, low-power, embedded devices will accelerate as MEMS technology becomes available, with almost microscopic devices able to sense numerous electromagnetic fields, position, velocity, and acceleration, and communicate with substantial bandwidth in the near area, powered by ambient energy in their environment. Larger, more powerful systems within the infrastructure will be driven by the continued improvements in storage density, memory density, processing capabil-ity, and system-area interconnects as single board systems are eclipsed by complete sys-tems on a chip. The interconnect between will become not only faster, broader spectrum, and more ubiquitous, but smarter as processing is incorporated into the network. System design can no longer focus on a "typical" device with an average amount of processing and storage capacity and a standard array of peripherals. We need a major reorientation of the fundamental systems software that manages operations within these devices and their communication, oriented toward dealing with the flow and transformation of streams of information in a continuously adaptive, self-managed fashion.
Data movement and transformation is of central importance, not processing. Future devices will be network-connected, channeling streams of data into the infrastructure, with moderate processing on the fly. Others will have narrow, application-specific UIs. They will be highly adaptable and configured automatically, and yet provide strong guarantees of availability and performance. Applications will not be centered within a single device, but stretched over several processing locations, forming a path through the infrastructure. The OS must be small, fast, and agile for operation on a specific device. We will demonstrate a novel OS architecture that will allow rapid development of new applica-tions on devices that integrate smoothly with a powerful infrastructure. Four elements shape the architecture:
(i) The central concept is a path for information flow, rather than a thread. Threads exist to set up flows and control structure for paths. The scheduling and processing steps are the state transitions moving data. Scheduling is simple and predictable, since bounded work is posted at discrete intervals. Providing atomicity is simplified because entire state transitions are atomic. A clean framework is provided for graceful degradation in the presence of failures. However, partitioning the applications into easily scheduled entities becomes the responsibility of compilers, enforced at run-time. Strong guarantees can be made even for dynamic mobile code, since the processing is highly constrained.
(ii) Persistent state is provided in the infrastructure, with soft state on the device. Communication operations provide access to persistent state, wherever it is. A separation is made between consistent and highly available state. Separation allows degraded operation to be handled differently, reducing responsiveness or accuracy. Rather than files, storage is organized around typed persistent objects, implicitly versioned, and flows.
(iii) All system functions are non-blocking, with no application state in the kernel. This is not present in existing OSs, and yet has proved essential for small devices to huge federations. Explicit management of all state by the application (or path) enables migration of code for extensibility, fault recovery, and operation in unexpected environments.
(iv) Functionality not within the device is accessible through a non-blocking remote method invocation. This allows functionality to be dynamically associated with hops in a path, rather than pulled into each device. Mobile code enables movement of functionality along a path, blurring the boundary between device OS versus infrastructure services.
The functionality of Option 1 is essential for all other options. In developing it, we will pursue a process of iterative design, implementation and evaluation. In Year 1, we will develop a prototype system and initial architecture in a testbed consisting of commercial devices connected through proxies to a large cluster. This will include two native implementations for specific Information Devices, with the remainder emulated on existing OSs. We will develop detailed simulations for a broader range of system organizations. In Year 2, we will incorporate MEMS sensors/accelerometers interfaced to small devices in a first generation flow-based run-time environment. It will be demonstrated in a pro-totype room-scale environment for capturing occupant hand gestures (a kind of wearable 3D "mouse" supporting the physical activity spaces of the collaboration and learning ap-plications of Options 5 and 6). The finger-based MEMS devices communicate to a wrist transmitter, that in turn communicates with the room-scale infrastructure. In Year 3, we will provide a full demonstration with MEMS devices and infrastructure-based persistent storage on a ten-finger, untethered gesture-based environment.
Future users will focus on communication and information flow, not files and data. The Oceanic Data Utility provides nomadic data access (serverless, homeless, and freely flowing through the network) to a ubiquitous, unified pool of persistent objects. Data correlations that are collected by the underlying system (e.g., Option 5) are exploited for optimistic data distribution, intelligent prefetching and informed cache management that optimizes data location based on usage.
The Data Utility commoditizes information storage, through composition of multiple, independent service providers. For a small fee, users rent data storage residing "in the net." Although data is free to migrate anywhere within network, individual service providers are responsible for providing backing store for their client's data and for guaranteeing reliability of that data. Bandwidth and temporary storage resources are traded freely between service providers via a computational economy; accounting mechanisms track re-source usage, ultimately distributing user fees back to service providers.
Nomadic data properties include: (i) promiscuous caching (data cached anywhere, any-time ), (ii) freedom from administrative boundaries (data is administered, not physical resources), (iii) high-availability and disaster recovery (data resides in multiple loca-tions; its distribution and replication is chosen to minimize correlated data failures, (iv) data consistency (support for application-downloaded techniques for conflict resolution, from traditional database-oriented ACID semantics to weak forms of "eventual consistency"), and (v) security (data never resides in cleartext anywhere except at endpoints; it must include signatures to prevent corruption and/or spoofing). Data naming is completely divorced from the physical layout and indexing mechanisms. This facilitates transparent reorganization, indexing, and caching, as well as the judicious exploitation of low-level sharing mechanisms such as multicast.
The critical challenge is data location and consistency. We will solve the data indexing problem with a confederation of overlapping, partially-consistent data indices, backed by infrastructure-based data location agents. Individual indices will be constructed with randomized data structures that have good average behavior. By allowing indices to be overlapping, each pool adapts its own index to the access patterns of local clients. By allowing indices to be partially out-of-date, data can rapidly migrate from place to place. When data cannot be located in an index, scans of indices at ever greater distances are referenced, driven by tacit information and/or hints of the last known data location. Search engines will be reconceived as repositories of hints of where to start looking for data. Information utility providers ultimately are responsible for indexing and advertising the existence of their user's data to these. Indices are stored in the data utility along with the data that they describe. Hence, they can make use of conflict resolution protocols to achieve eventual consistency. Data indices may be the partial or complete embodiment of the tacit information of Option 5.
The Oceanic Data Information Utility extends the fluid processing paradigm of Option 1 to pervasive storage throughout the infrastructure. The storage intensive aspects of Option 3 and the Applications of Options 5 and 6 depend on this functionality for their suc-cessful implementation. In Year 1, we will explore the design alternatives for pervasive and nomadic storage. In Year 2, we will implement a first prototype. The utility will be distributed on data servers within the Berkeley Millenium "clusters of clusters" hardware, to explore the performance of the Oceanic Information Utility in the wide-area. In Year 3, we will measure and evaluate it, based on its usage by other components of the Expedi-tion, in order to develop a more refined architecture. At this stage, we will determine the possibilities of deploying a larger scale version, enabled by placing servers at geographically diverse locations.
MEMS technology will revolutionize the volume and detail of data available from sen-sors. We will have millions of tiny, virtually free sensor nodes capable of modest band-widths, but aggregating into huge bandwidths. While MEMS "hardware" is progressing rapidly, the limiting challenge is to unify such sensors with software that extracts, man-ages, and analyzes vast streams of generated sensor data. These must operate at enormous scale, and must be flexible enough to handle the hardware vagaries of sensitivity and noise, the on-board ability to compute or filter, and the erratic data delivery rates.
Scenario 1: Merchandise Tracking
Supply-chain management is one of the largest scale uses of databases, to streamline the flow of goods from manufacturers through the retail chain to customers. By tracking the goods through stores, retailers ensure that each store has sufficient goods in stock, elimi-nating warehousing. This dramatically reduces costs, yielding competitive advantage to those who effectively harness this technology.
MEMS can advance this considerably further. A MEMS sensor will be embedded in many future items. Each tagged item will generate a lifetime stream of information, transmitted periodically to the manufacturer and vendor. Goods will be individuated: rather than counting how many Furbys are on the shelf, each will have a unique identity and tracking history. Some of an item's information will reside permanently with it, for eventual use in special cases (e.g., warrantee service checking for evidence of misuse). Other information will be captured and stored by the infrastructure, and made available valuable to merchants and vendors.
Scenario 2: Capture and Reconstruction of Events in the Field
Remote and unobtrusive sensing has many applications. MEMS "smart dust" can blanket a region with sensors, detecting movement, noise, light, air composition, magnetism, etc. Such devices enable two alternative modes of data analysis: (i) isolated object-by-object analysis, such as a smart land mine that detects an unidentified human and detonates), and (ii) complex aggregations of data collected and processed by very large numbers of sensors. The former is commonly achieved today; the latter is our long term goal. MEMS sensors offer the possibility of capturing reality in extremely fine detail, enabling its re-construction to any detail level. This is an intriguing alternative to "virtual reality"-"real reality" played back, with far more information content than simple video and audio.
Challenges in Data Collection and Analysis
The data management needs of sensor systems is fundamentally different from today's practice. The huge data volumes are the most significant differentiator. MEMS generates far more data in real-time than can be reasonably stored. Thus a fundamental challenge is scaling up the processing and storage architecture (Options 1 and 2), while simultane-ously applying aggressive data reduction techniques to judiciously filter and aggregate sensor data into more compact representations. This involves combining data modeling and data mining approaches with extending the data management system with new kinds of operators for signal processing and filtering.
A second challenge is supporting data management operations natural to sensor data. Traditional databases can't analyze the kinds of infinite-length sequenced streams generated by sensors. Sensor-centric systems need to be designed for streaming flows of data (Options 1 and 2), optimizing running results, rather than final answers. Data flow is a key architectural principle: there are no blocking operations (e.g., sorting), and all sources must have data flowing simultaneously.
A third challenge is managing the noise in sensor data. No sensor will communicate at a regular rate, and its readings may not be trustworthy. The basic data management opera-tion will not be query answering or data mining, but rather evidence accumulation. This involves developing completely new techniques for data aggregation and filtering. We will investigate both general-purpose and application-specific techniques. Given the ex-pedition team's expertise in compilation and automated synthesis from high level specifi-cations (Options 1, 7), we will investigate whether application-specific aggregation and filtering techniques can be automatically synthesized.
The last challenge is the system's distributed nature. A single server collecting data from a large sensor array is both a performance bottleneck and a single point of failure. A bet-ter approach is to automatically organize a distributed confederation of processing and storage agents across administrative domains to cooperate on data capture and analysis. This builds on the fluid software of Option 1, nomadic storage of Option 2, and the cooperative components of Option 4.
In Year 1, we will investigate the special data management needs of large-scale sensor arrays, and will use this to develop an initial specification for an extended data manage-ment facility for their support. In Year 2, we will implement an initial prototype, using the technology developed for Options 1, 2, and 4. This first prototype will be used, in part, to support the applications being developed for Options 5 and 6. In Year 3, we will evaluate the system in this applications context, and will iterate the design and imple-mentation to develop a refined specification for sensor-centric data management.
A fluid information utility is a fabric of millions of hardware and software components. Each component cannot be manually configured and administrated. They must be configured automatically, in relation to services provided by others, while adapting to environ-mental changes, including the quality of their interactions with others.
We envision an environment in which each component specifies its needed services, and the services it can provide and to which other components. Components will automati-cally find others with whom they can confederate, using a negotiation protocol to determine the form of the services they will offer each other, and under which conditions. This results in flexible self-configuration. Each component automatically determines not only who will provide its services, but its own role in the overall system.
For example, a device with a small, relatively transient memory (e.g., a digital camera) specifies that it needs another device to act as its persistent store; that device specifies its desire to act as an archive. The negotiation architecture provides mechanisms for the (i) rendezvous of components with needs and components with services to offer, determination if they should confederate, and (iii) establishment of a configuration. Once a configuration is established, components monitor its performance, providing dynamic, adaptive responses to changes in the environment. This allows systems to degrade gracefully in the presence of failure, as well as to improve their performance as new capabilities are discovered. These mechanisms will make future systems much less brittle than today's. For example, when a component fails to provide a service as contracted, this will be detected, and an adaptive strategy deployed. Contract monitoring might be pre-emptive; a disk system nearing saturation could send a purchase order to acquire more disks.
We will develop a negotiation architecture to enable such auto-configuration. This is a set of protocols and services that conforming components use to perform the following: (i) specify the potential services they provide, the terms and conditions, and to whom, (ii) disseminate the availability of these services, (iii) specify the services they require, and their terms and conditions, (iv) discover other objects that provide required services, (v) allow objects to enter into multi-phase negotiations of contracts, committing to provide services under terms and conditions, (vi) provide compliance monitoring services of contracts, and (vii) provide means for dealing with non-performing confederates. To imple-ment the architecture, we will develop: (i) a language for specifying services, and their terms and conditions, (ii) a protocol for negotiating contracts between objects, (iii) infrastructural services, including discovery, service availability dissemination, and compli-ance monitoring services, and (iv) means to adapt to a non-performing service.
To facilitate reconfiguration capabilities in information components, we propose imple-menting a contract designing agent. This produces standard, parameterized "boilerplate" contracts between components, and assign standard "compliance officers" to them. For example, a standard contract specifies that requests of a certain sort must be responded to within a certain period. If enough such requests are not honored, then the component seeks services elsewhere, perhaps via a pre-negotiated option contract with a third party. Including such a contract is all the designer need do to ensure some adaptability.
We will do the detailed design of the negotiation architecture in Year 1. A first imple-mentation will be performed in Year 2, in support of the activities of Options 3, 5, and 6. These applications will provide the context for evaluating and evolving the architecture for a refined specification and prototype implementation in Year 3.
A corporation's information assets include its explicit data and the tacit knowledge embodied in its workers and institutional practices. E-mail, groupware, databases and http improve access to and dissemination of information. But effective usage remains a prob-lem. Different groups might work on related tasks without being aware of each other. In-formation flows rigidly along "lines of communication." Social barriers exist, such as judging information reliability and the difficulty of interpreting documents without access to the context in which they were developed. With the deployment of groupware tools, information about the flow of information can be mined to improve collaborative work. Such tacit information makes it possible to: (i) organize information so it is in a form that is available to users, (ii) infer the level of communication between people and informa-tion sources to manage the level of "awareness" between computer-based and human agents, (iii) infer indirect relationships, such as two people accessing the same set of sources, making this known to principals for information and work-sharing exploitation, (iv) organize data location so communication and latency are minimized, e.g., activity-based management pre-fetches likely data before use, and (v) infer the availability and participation level of human decision-makers in real-time, supporting opportunistic not calendar-driven decision-making.
Collaboration Applications based on Activity Spaces
Activity spaces use non-literal 3D representations for activities, people, and information sources. Levels of awareness correspond to the strength of the tie between human and agent (human or information source). Closer agents are depicted in more detail, with more frequent information updates. These ties are inferred automatically, but are user-adjustable. This is used to make the best use of each participant's limited attention.
The strength of ties between agents are determined by cues: (i) number, length, and topic of e-mail between people, (ii) frequency of work in an activity space, and (iii) frequency of access and attention, estimated from reading time, for information sources. Cues are useful for locating data near participants, as well as managing awareness and notification level. The strength of each activity tie dictates how frequently notification is received. By pushing the activity away, a user reduces ties to her agents to concentrate her attention elsewhere.
Implicit knowledge can be exploited to establish authority. Centrality, the flow of authority in an organization, has been discovered in the context of on-line and digital documents. We will extend concepts from social network theory for managing this kind of implicit knowledge. We can use techniques from pattern recognition (e.g., dimension-ality reduction, spectral clustering, low-dimensional embedding, etc.) to compute cen-trality from tacit data. We will track the social network, including information flow, that leads to document creation. These dependencies are useful to others trying to understand the context of the document.
Implications for the Information Utility and Information Devices
Tacit knowledge mining requires fine-grained acquisition and coordination of human ac-tivity. It must be captured, forwarded to the appropriate analyzer, and stored for later use (Options 1, 2, 3). Much of the data is sensitive; inappropriate information must not be extracted from the system. Since there is no central authority, each entity must authenti-cate itself and its reason for requesting the information. Computational support for an activity should follow it. Secure client code migrates to the activity site.
Activity spaces leverage specialized information devices (Option 1). Digital whiteboards are popular collaboration tools, and are commercially available. A range of emergent wireless devices will support simple information requests (e.g., cell-phones with en-hanced displays) as well as spontaneous collaboration outside of regular meeting rooms (e.g., larger writing/reading appliances and portable projectors/whiteboards). Wearable appliances should be aware of the activity that the owner is conducting, by communicat-ing with other devices used in that activity. Devices should be intelligent about inter-rupting current activities, e.g., instead of ringing, a telephone should inform the caller that the receiver is in a high-priority meeting, or is working against a deadline, or is not busy at the moment.
In Year 1, we will design our first generation activity space in hardware (a single collaboration room) and software (applications for group collaboration visualization and man-agement). In a collaboration with IBM, we will undertake pilot studies on tacit informa-tion mining to learn how IBM's Almaden Research Center itself makes use of Lotus Notes, an industry-standard groupware package. We plan to deploy Notes throughout the EECS community. In Year 2, we will perform extensive usability evaluations of our ac-tivity spaces, and use these experiments to design second generation room and applica-tion support capabilities. The Notes experiments will allow us to refine our mechanisms for tacit information extraction. In Year 3, we will opportunistically deploy multiple refined activity spaces outside of the Berkeley EECS community. We will use them for group brainstorming activities, like proposal writing. This will allow us to evaluate the usability of the technology by a more diverse user community, and will permit us to un-derstand more about the differences among collaborations inside and across physical spaces.
Technology must play a role in transforming the educational system to meet the challenges of the next century. Most proposals build on the traditional lecture, achieving only minor improvements. We will combine problem-based learning, where small groups of students work collaboratively to teach themselves, with revolutionary information appli-ances to make learning more fruitful. This Electronic Problem-based Learning (EPBL) vastly improves student learning while requiring fewer teachers and facilities.
Problem-based learning (PBL) shows impressive results in educational outcomes, but it does not scale. Teachers serve as facilitators, planners, and tutors to groups that need help. They track and critique materials produced by the groups, monitoring their informal interactions. We propose to build electronic tools, based on the technologies developed in this proposal, to capture the materials and interactions of groups (Options 3) and store them in the Information Utility (Options 1, 2). When combined with analysis, communi-cation, and collaboration tools (Option 5), EPBL amplifies the teachers' ability to give personal attention to more groups.
Inputs to EPBL spaces will come from task-specific Information Devices, spanning from A/V capture and playback devices to PDAs, tablets, laptops, and workstations (Option 1). These also enable "mobile classrooms" where students remotely use EPBL during field-work.
Tacit knowledge is applied to combine information across student groups (Option 5). This allows individual students to leverage the experiences of others. Bayesian learning techniques will be combined with tacit knowledge exploitation to automatically identify those groups needing personal attention. The system presents materials to each student in ways that are better suited to their strengths. These tools help reduce the volume of inter-actions between students and teachers, while increasing the quality of the interactions.
Technical Approach
We will develop technology for student exploration, collaboration, and problem-based learning in the future classroom. It will be reconfigurable, exploiting technology to make learning more productive. It will support small group teams as well as occasional large collaborations and presentations, involving local and remote participants. The classroom will support student use of diverse devices. Within this applications area, we will address the following challenges:
Our success will be measured by how well we scale the classroom to larger numbers of students, while improving the interactions between the students and the teachers. We will evaluate learning effectiveness in terms of speed of learning for one of Berkeley's design classes, comparing groups of students with and without access to the enhanced learning activity space. In Year 1, we will build an information appliance enabled classroom, and teach a course where students watch recorded lectures at home, using class time for group work and feedback. We will design collaboration tools for project work, developing pro-totype applications and infrastructure support for interesting devices. In Year 2, we will replicate the classroom, potentially in a mobile format, leveraging Berkeley's high band-width connectivity to other schools and research organizations to bring outside students and experts into the learning environment. We will evaluate the gains from using this en-vironment. In Year 3, we will deploy wide-area versions of our applications. These will be used to bring outside experts and students into the environment.
Information Devices are powerful activity- and task-specific objects, containing embed-ded software and electronics to sense and actuate the world. Bringing such devices to market rapidly requires new programmable components and support tools, enabling faster software development that is correct and safe the first time. Tools for quickly developing powerful and friendly user interfaces are also essential. Embedded systems contain ASICs designed with synthesis tools. As complexity scales, these won't be designed from scratch. Hardware and software design re-use is the key to low cost, rapid implementa-tion. Designers and manufacturers will exchange Intellectual Property in the form of component hardware/software designs rather than complete chips.
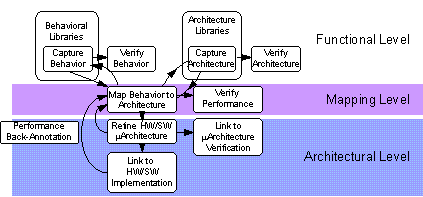
We have been developing a general design approach that is based on formal models to describe high level system behavior before its decomposition into hardware and software [Balarin97]. The essential conceptual breakthrough is the use of a new modeling tool, the Co-design Finite State Machine (CFSM) to describe systems at a high level that are glob-ally asynchronous yet locally synchronous. The CFSM replaces traditional synchronous communications with finite, non-zero, but unbounded reaction times, and has been suc-cessfully used to model both hardware and real-time software. It has applications as a specification language for the fluid software paradigms of Options 1, 2, and 3.
The design sequence is an initial functional design and analysis, its mapping into an ar-chitecture, and a performance evaluation. Automatic synthesis ensures implementations are "correct by construction." Validation, by simulation or verification, is performed at the highest level of abstraction. See Figure 3 for the design flow. To verify the viability of our design method, it will be used to design new Information Devices for Option 1.
The software of the Information Utility will be a collection separately constructed com-ponents written by many people at different times, and sometimes with unstated assumptions about the environment in which they are used. Understanding in detail the possible failure modes of such a complex system is beyond the scope of any individual program-mer or even a talented team of programmers. To be economical, the information appliance must reuse existing components. It is inevitable some of these will not function as expected, undermining the robustness of the full system.
Recent advances in automatic software analysis have made it possible to analyze large software systems in detail, helping identify faults and verify global invariants that are too difficult or tedious to check by hand. To help accelerate development of the Information Utility, we will develop and deploy a programmer's assistant incorporating this new technology. Programmers will be able to state and statically verify application-specific properties over the entire multi-million line code base. This tool will be used to assist in decomposing monolithic systems into components for invocation on paths (Option 1), as well as the basis for generating and verifying interface contracts (Option 4).
We will also develop new design approaches for information device UIs. Ours will be based in part on model-based user interface tools. Abstract models are used to specify an interface, from which UI code is generated depending on application data and design rules. Such model-based tools are not widely used, because they force designers to think abstractly about their applications during the early stages of design and the specification languages resemble programming languages, which are inappropriate for UI designers.
Designers commence an interface design by sketching examples of the important screens and scenarios. Such specifications are abstract because they are ambiguous and are only rough representations of the intended design. On the other hand, they are concrete exam-ples that map to a particular technology that the designer has in mind (e.g., a PDA user interface). We will abstract from the sketched examples to an interface model. We can then use this to generate the proper interface on any target device. We will extend the model-based tools research to properly support the generation of interfaces that are mul-timodal and that will run on a variety of devices. Our code generator will make substitutions based on the multimodal capabilities available on the target device.
In Year 1, we will study the design approach to determine the tools that will be needed to support the effort. We will commence an initial design of the system and of the design flow in collaboration with the other members of the team. In Year 2, we will prototype implementations of our design tools for early user testing in our group as well as in appli-cations domains. We will select applications to be the target of a design, e.g., the wear-able pointer of Option 1, an electronic book for Options 5 or 6, or a smart vehicle used as remote locale for participating in collaboration sessions or learning environments. In Year 3, we will iterate using the early results. We will redesign our target applications and complete a more finished version of the tools, the underlying architecture, and the test applications. Finally, we will distribute and test our final version of the tools to de-signers at UC Berkeley and interested groups elsewhere. In this context, we will conduct further evaluations on the effectiveness of our design tools.
This option supports deploying our developed technologies in a substantially larger scale testbed than the single "smart" room in the base program. The scaled testbed provides: (i) extensive opportunities for studying the impact of our technologies on a larger and more diverse user community, (ii) a much higher level of usage to stress test the component technologies, and (iii) a driving force for a true utility upon which others would depend.
The base program develops a single room-scale testbed, to be used as a physical space for group brainstorming and learning applications constructed on the Information Utility. We see three increasing levels of scale-up to be pursued:
Building-Scale Testbed: Virtually everywhere within Soda Hall (or its extensions through broadband connectivity to residences) will be able to access the Information Utility. An experimental collaboration room serves 10-20 participants. The whole building has 500 occupants, performing day-to-day administrative tasks, brainstorming on research, learning in classrooms, studying in lounge areas, etc. Such a community represents a richer environment from which to extract tacit information across a wider variety of ac-tivities. It demands that the system be able to handle an order of magnitude more proc-essing and storage, and provide a wider range of adaptable services.
Campus-Scale Testbed: The next scale-up is to the full Berkeley campus. This progresses in stages, first incorporating Cory Hall (the EECS Department's other building), adding South Hall (the home of the School of Information and Management Systems), and other spaces on campus, such as the Libraries and the Dining Commons. The Millennium Proj-ect already provides high bandwidth connectivity to several sites around campus. Addi-tional processing and storage will be needed for the larger intended community. Deploy-ing the elements of the Information Utility outside of the immediate Berkeley EECS community implies that a higher level of system support and associated full-time staff will be necessary, as we cannot expect the user community to be as forgiving as our local users . Fortunately, this will drive the system architecture in two critical dimensions: "always available" operation and administrative scalability.
City-Scale Testbed: The next scale-up is to the City of Berkeley, with 120,000 residents. Berkeley's Interactive University (see http://iu.berkeley.edu), supported by the Department of Commerce's National Information Infrastructure Grants Program, is establishing high bandwidth connectivity between campus and schools in Berkeley, Oakland, and San Francisco. Its goal is to provide access to the University's libraries and classrooms to teachers and students in K-12 education. It provides an excellent scaling opportunity across a wider area, to a more diverse user community, yet still focused on our key driving applications of brainstorming and learning environments. Such a testbed makes significant demands on administrative scalability and system ease-of-use. Once outside the University environment, these become critical issues limiting the dissemination of infor-mation technology.
The proposal team has been in independent discussions with representatives of AT&T and Motorola to consider the City of Berkeley and the Berkeley Campus as sites for de-ploying large-scale testbeds, providing high speed access from campus to sites through-out the city. DARPA's investment in this option will be highly leveraged by additional equipment and deployment expertise brought to bear by our industrial partners. We have factored this assumption into our budgeting for the option.
This option only becomes active in Year 2 of the proposed expedition, to allow some time for the most promising technologies to mature and for the Information Utility archi-tecture to solidify. Progress through Year 1 would shape the detailed plans for the scale-up option in Years 2 and 3. Should this option be selected, we would construct the room-testbed on an accelerated schedule in Year 1. Extensive usability evaluations would be undertaken at that time. We would then use this experience and the associated evaluation to replicate that design throughout Soda Hall during the first half of Year 2, and the Berkeley campus during the second half of Year 2. Again, extensive usability evaluations would be undertaken to insure that the environment can be used effectively by a more diverse user community. Experience gained in constructing this campus-scale testbed would be used to refine the design and implementation of other enhanced spaces that would be inserted into selected schools and other public buildings in the city in Year 3. Final evaluations would be completed at this time.
Randy H. Katz, 17 July 1999, randy@cs.Berkeley.edu